


国睿信维睿知知识工程系统软件——REACH.KES产品介绍
发布日期:2021-03-01 浏览次数:2352
一、研发背景
工业技术是现代制造业的灵魂,代表着制造业先进生产力,也是国家制造业竞争力根本所在。在知识经济时代,作为知识密集型产业的制造业对知识积累、共享的需求日益增加,企业竞争的核心从传统资源转变为知识资源。知识的重要性日益凸显,并已经成为最有价值的战略资源。
然而,绝大多数企业在知识管理建设方面举步维艰:企业缺乏知识积累的手段,员工知识整理和存储的意识比较薄弱;知识可用性差,员工发现知识的代价过高;企业未能形成长效的知识管理机制与文化,知识难以得到持续积累与创新。
随着企业知识管理内外部环境的变化,传统知识管理的核心思路应围绕价值认知、目标定位、知识形态、运营策略等方面进行变革。国睿信维看到了中国工业制造业企业对于知识管理共享化以及知识服务化的迫切需求,基于知识产品化思想,推出针对智能研发业务过程操作、利用知识构件及自然语言解析、机器学习等技术手段的知识工程系统-REACH.KES,推动知识工程方案的有效落地。
二、产品定位
REACH.KES系统是充分利用知识图谱、自然语言处理等新一代IT技术及手段,把企业里散落在不同平台的各形态知识进行有效地组织、加工、利用,并充分结合不同角色的应用场景,提供丰富的知识构件服务,提升企业发现知识的概率,使知识在企业中真正地流通起来的知识产品。
知识工程的核心是企业知识实现增值。为了达到这一目的,国睿信维引入了最新的IT技术,主要依托自然语言处理的语义解析功能,通过三元识别构建本体库,利用词汇处理的技术对文档类知识进行标引。同时,建立关键词表,基于机器学习能力,提高分词准确性,使REACH.KES拥有自动摘要和自动索引能力,实现知识获取和加工的自动化。基于语义的智能检索、主题关联和知识推送,解决海量数据处理形成知识,知识难以发挥作用等难题。
在知识工程实施过程中,员工所需的资源从初级知识转变为精加工知识,对知识的诉求已经逐步从“知识学习”向“知识消费”进行升级,大多数员工更为希望能够获得解决当前棘手问题的答案,而非是从海量的知识中寻找“心仪”的知识。因此,国睿信维认为,REACH.KES的一大核心就是进行知识的加工、组织,结合企业自身知识资源特点及应用需求,提供碎片化、组织化、结构化、关联化的精准知识投送。
传统的知识管理中,知识过于泛泛,与工作关联关系较弱,员工必须花大量时间寻找并筛选有效信息。国睿信维认为,知识资源只有出现在正确的时间与位置时,才不是冗余信息,才能够真正被利用。因此,知识与工作需要强关联起来,融入业务流程中。REACH.KES主动在流程化研发过程中提供场景化知识,进行精准推送知识服务;以插件的形式在多个业务工具中,实时提供知识检索服务,真正满足用户对知识的需求。
三、产品能力
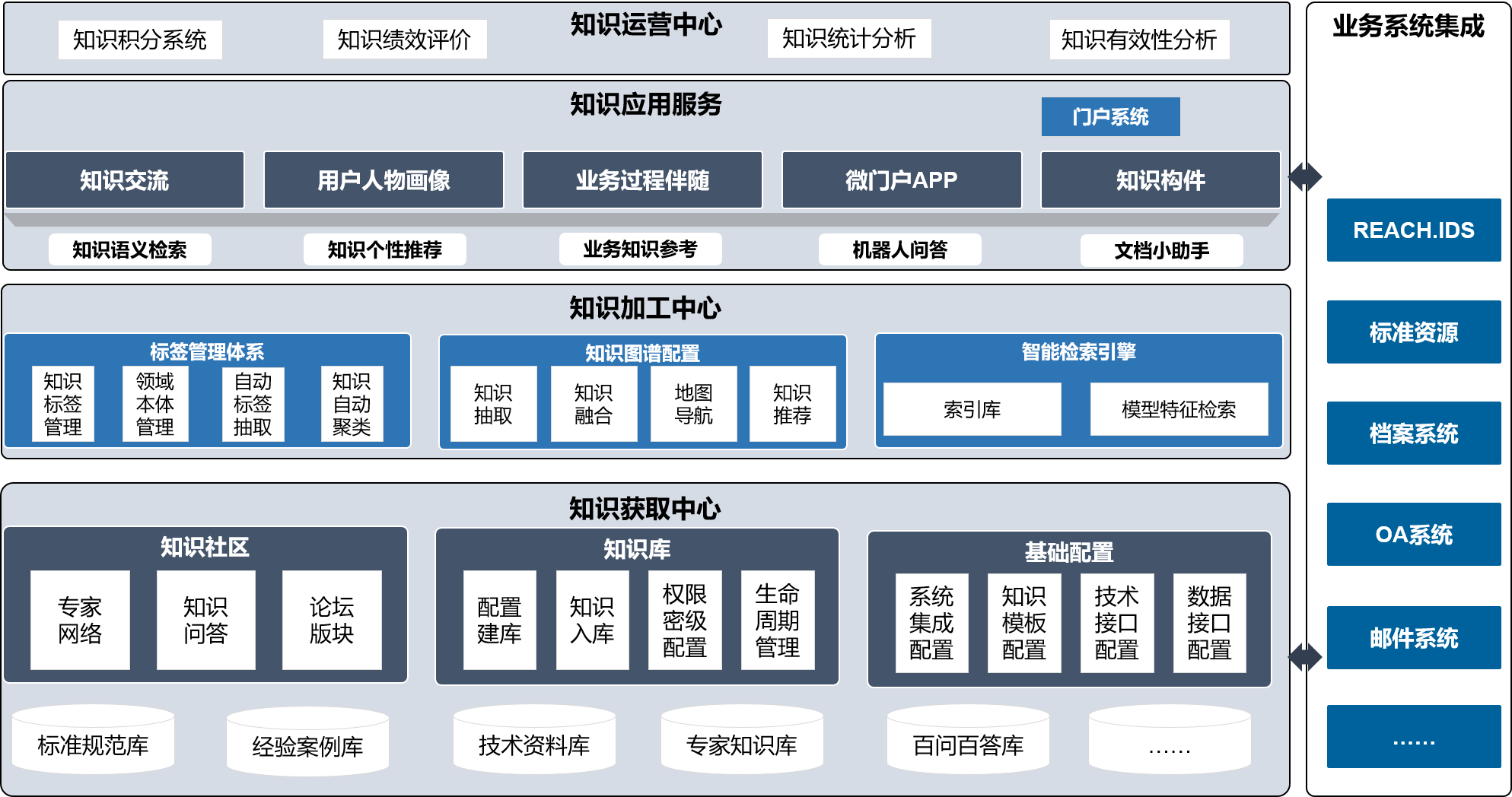
国睿信维REACH.KES有四层架构,第一层解决如何知识获取的问题,第二层解决知识加工的问题,第三层解决知识展现及应用的问题,第四层解决知识运营的问题。
(一)多渠道的知识整合能力
国睿信维提供多种自由获取知识的能力,我们将知识分为显性知识及隐性知识,显性知识是整理成册的书面表述,隐性知识是埋藏于企业专家、员工脑海中的经验与技术,需要平台将其显性化。
对于显性知识,REACH.KES通过实物类接口、数据类接口、信息类接口及技术类接口的方式,建立各领域知识的统一入口,能够从知识编辑、知识集成等方面实现各类知识的有效汇聚与规范。系统搭建统一环境,实现知识资源的集中化与标准化;构建多维的分类体系,使知识更容易被发现与传播;集成企业其他业务系统,采集所需的知识资源信息。
为了转化隐性知识,REACH.KES搭建完整的知识社区,为相关员工提供统一的知识学习、交流分享和应用平台。通过论坛帖子、讨论组空间将隐性知识社会化,通过人员的互动及交流,提炼出最佳实践经验和方法,促进企业隐性知识的不断显性化积累。通过知识问答及专家系统,实现企业内部专家知识的有效留存,避免企业核心知识资产流失,促进企业知识的不断交流与传递。
(二)灵活的知识加工能力
REACH.KES首先利用先进的IT技术对知识进行深度理解后的拆分,运用自然语言处的分词方法,自动提取关键字建立标签体系,并自动给知识打标签,从多维度、多状态对企业知识进行梳理。采用机器语言学习能力,深度挖掘海量数据并进行知识推理,通过分析文档主题、计算词语关联关系等多种方法实现知识的自动聚类。标签与知识、用户、部门灵活关联,结构关系可以多次人工配置。
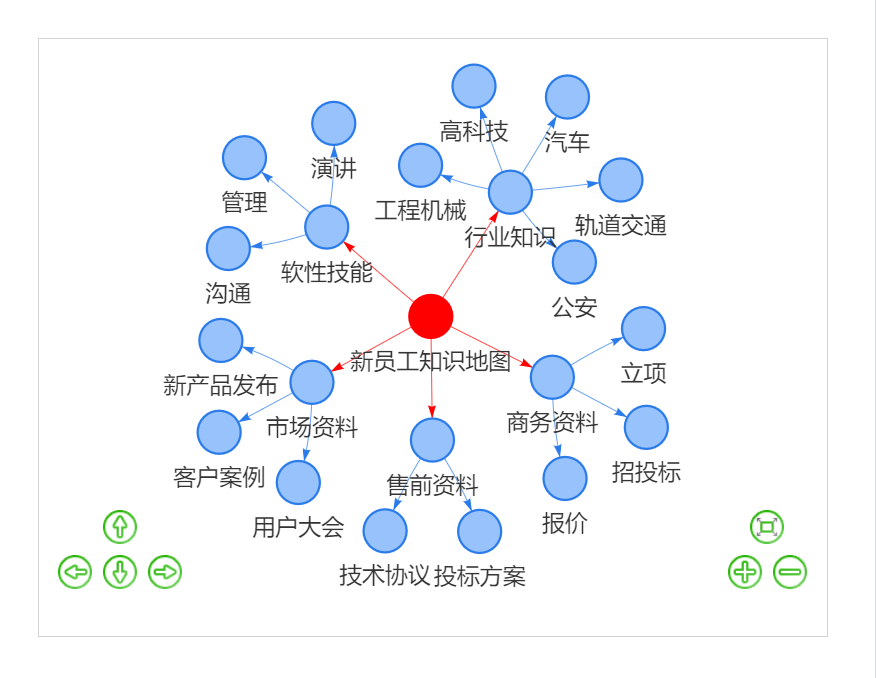
REACH.KES还特别通过知识图谱技术,构建一套覆盖企业核心业务领域的可视化知识资源网络,帮助企业建立面向不同应用场景的知识地图,达到知识导航目的,使得用户对知识的整体关联情况可以一目了然。
(三)沉浸式的知识服务能力
我们将知识应用服务分为五个层级。第一是基于传统知识管理系统的应用方式,即业务人员通过知识库聚类、标签主题、查询、导航、收藏、订阅等方式获取需要的知识。其中,REACH.KES的全局检索建立在基于语义分析的索引库基础上,对用户的查询表达进行语义推理,从而更加正确、全面地识别用户意图,实现知识精确检索。
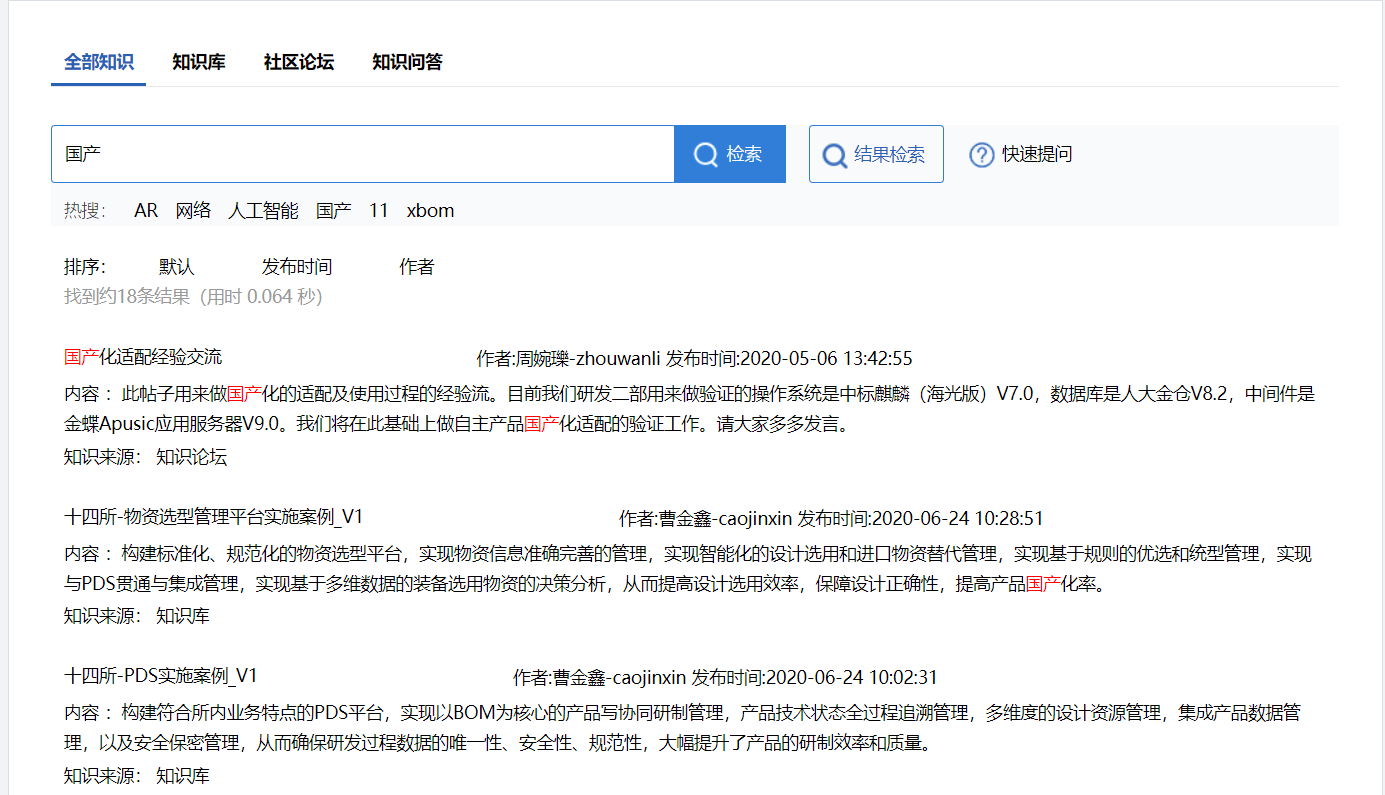
第二种是基于人物画像的知识推荐,REACH.KES根据用户的专业背景、部门岗位、历史知识行为、个人偏好等进行分析,构建业务人员个人画像,实现对员工个性化知识需求的理解,并基于标签设置的权重进行知识针对性推送。
第三种是基于流程的知识推送方式,即业务人员在工作过程中,打开工作包时伴随知识的自动推送。REACH.KES与REACH.IDS系统进行了集成,在项目计划中实时推送业务知识。以业务需求为导向,联系上下文,解决输入输出项难题,情景式推送知识,提高知识复用率及研发效率。
第四种是通过知识小助手的方式,提供知识的自动问答功能。利用知识微门户APP,使用户在机器人对话框中,能够自主查询,得到由系统解析后碎片化的问题回答,提供人机交互式的知识服务。
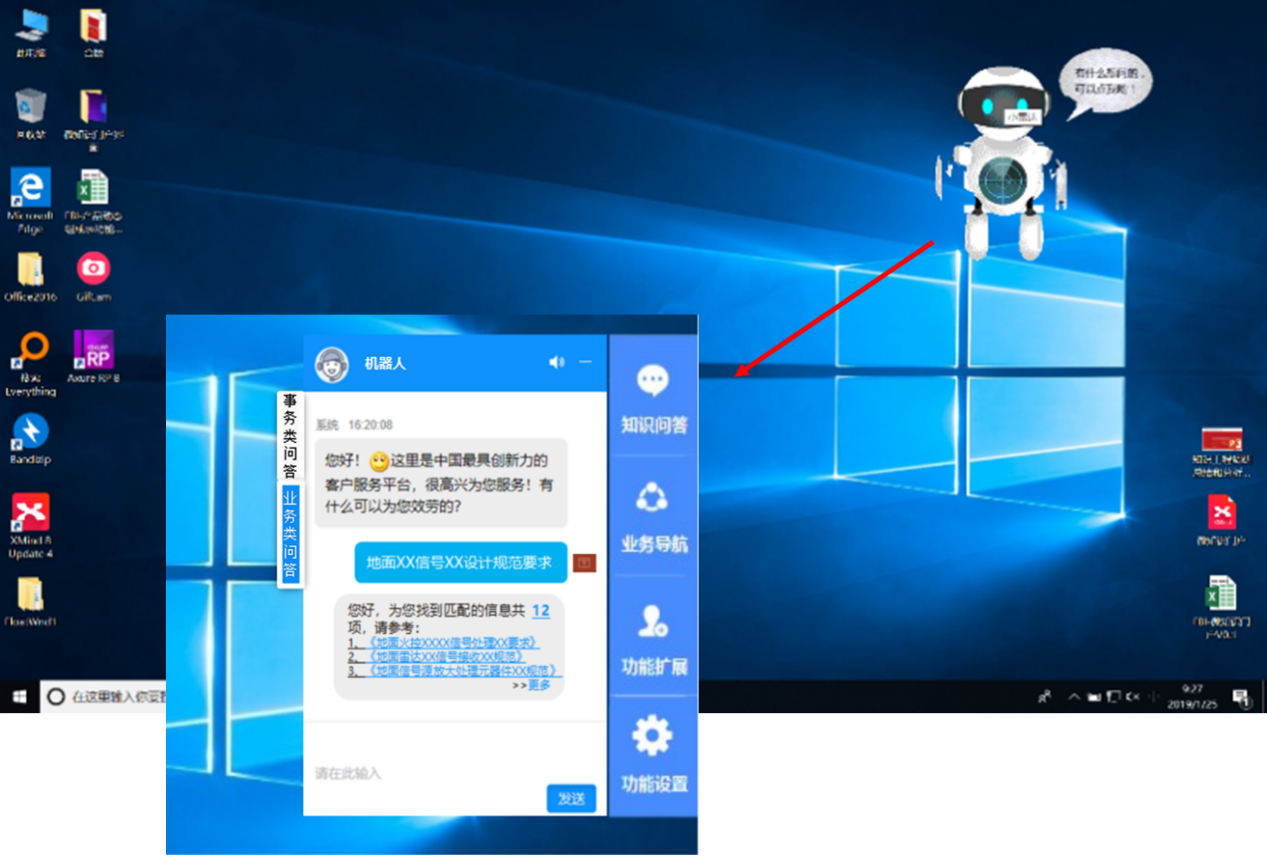
第五种是嵌入业务系统的知识构件,REACH.KES开发了文档小助手,在office软件中直接选中关键词,一键查询,返回待检索结果,实现人、知识、工具的场景化匹配。
(四)科学的知识运营能力
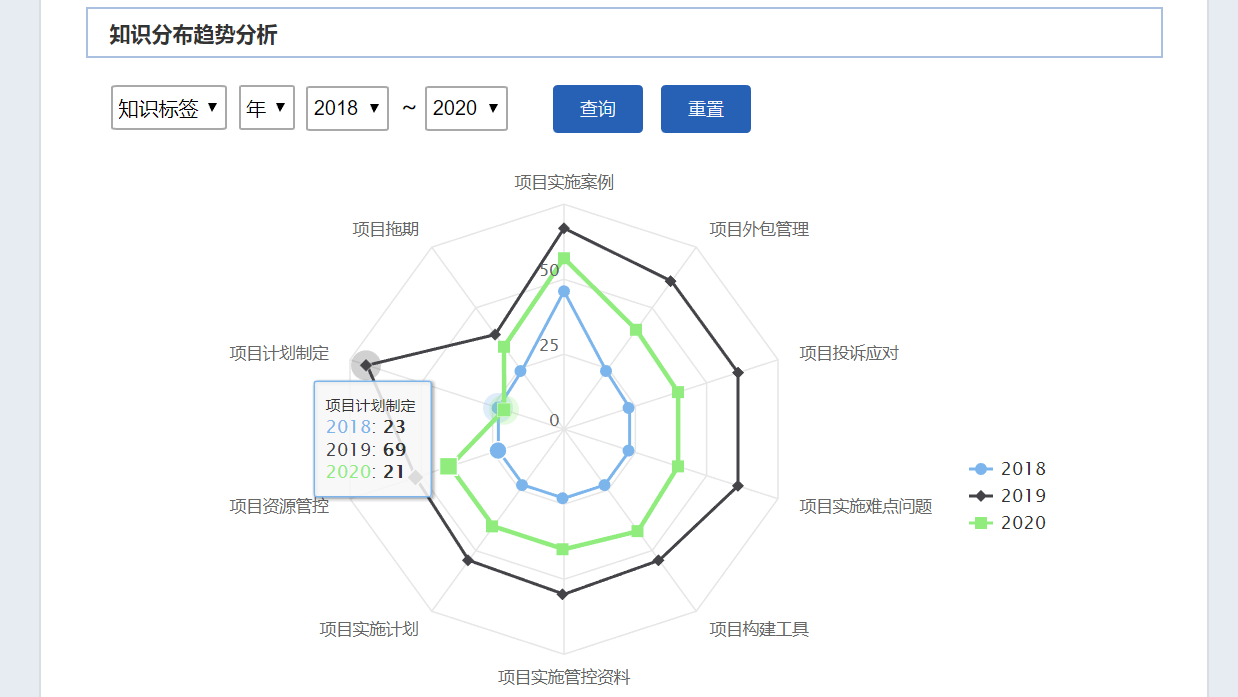
对于推进知识的有效运营,REACH.KES提供一套完善的知识治理体系和知识激励体系,利用积分系统和统计分析系统,鼓励企业员工参与知识提供,正向激励用户的活跃度,不断提高知识的数量和质量。通过虚拟货币与知识商城的结合,从物质、精神方面多种方式进行激励,促进建立员工乐于贡献知识、应用知识的企业文化。报表统计利用系统日志,全面分析企业用户在知识管理系统中的所有业务行为,实现对企业知识应用的各个方面和层面进行统计分析,用以评估知识的分布、积累、应用的状况和趋势。
四、产品未来
现在,国睿信维正在引进互联网行业内最领先的数据挖掘、数据接入及数据标注能力,从企业内部的数据中心、业务系统、工具或外部互联网中识别并提取实例,识别模型基本参数及特征,将其整理为结构化知识,增加知识获取范围的广度。同时提高自然语言处理的分词准确率,通过机器训练提升非结构化文档的三元关系识别准确度。为了更好地向中国工业企业提供符合产业需求的通用服务,国睿信维针对国军标文件定制碎片化信息能力,拆分标准规范文档,提取有效信息并结合业务场景,以段落、章节、语句的形式进行精准推送。国睿信维已经整合国内顶尖高校资源,在故障识别领域取得初步成果。围绕从产品、问题、人员、方法等对象视角,将设计、试制、测试、验证以及售后服务等过程的故障知识进行抽象关联,通过自动化的识别和挖掘手段,将分散的故障知识实体抽取到知识图谱实例数据库中。基于故障图谱,一方面能够支持设计师、质量师、装备维保人员对故障相关知识进行语义查找;另一方面能够与企业的相关业务系统集成。